最近在学习文本分类(聚类)的相关知识,所以接下来准备先写一个关于这个方面的系列博客。
写在前面:
先介绍下由我们四个人组成的组织:FOUR ELEMENTS。四元素分别对应WELL、EARTH、AIR、FLAME,根据首字母缩写,我们的博客主页得名WEAF。
接下来介绍下我自己,我叫Leno,对应于四元素里面的Well,目前研究生在读,方向为智能信息处理。我的博客主要会以日常遇到的问题以及学习的知识为主。
简单的介绍:
首先,我们要做的是对中文文本的聚类,如果做聚类的话,我们需要对文本的内容做分析,而分析的最小单位肯定是词。
其次,中文和英文的词是有区别的,最大的区别就是中文的词与词之间并不是用空格分隔开的,而且由于中国文化的博大精深,切词的时候我们需要考虑的词语组合情况就更多了。显然让我们自己去造一个这样的轮子有点不现实,其实像这样的工具,前辈们已经为我们做好了,而且超好用。
本文介绍的就是jieba中文分词,正如它的口号那样。如下图所示: 
当然,这里有两本秘籍GitHub && OSChina,既然你我有缘,便免费赠予你。
安装
这年头,没有什么是一句pip install 解决不了的。不管2或者3,直接pip即可。
1 | pip install jieba |
结合官方Demo理解jieba的三种切词模式
三种模式:
- 精确模式(默认模式):它会试图将句子最精确的切开,适合文本分析。
- 全模式:不考虑歧义,这个模式会将所有的可以成词的词语都扫描出来,因而速度会非常快。
- 搜索引擎模式:该模式是在精确模式的基础上,对长词再进行切分,提高召回率,适用于搜索引擎分词。
官方Demo:
1 | import jieba |
结果:
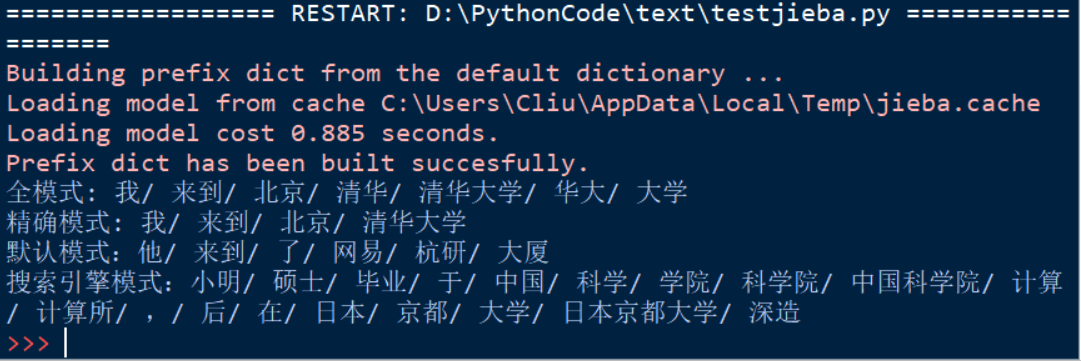
模式分析:
这里我们先分析这三种模式,对于cut方法的讲解在后边会给出,so不要问我为啥不给出cut方法中第三个参数HMM。
通过对比前两条输出可以看出全模式情况下,它会找出所有可以组成词的划分,而精确模式与其对比给出的答案就会很清爽。所以结合上文所说,不难理解这两个模式的区别。
接下来我们看第四条输出,它是在精确模式的基础上对长词再做的划分。所以‘日本京都大学’,它会再次切分为‘日本’,‘京都’,‘大学’三个词,同理适用于‘中国科学院’。所以这个模式也不难理解吧。
补充分析:
最后看第三条输出内容,也许你会问,既然知道默认模式是精确模式了,为啥还要给出试例,况且还是一个不具有对比性质的对比。这里其实想说明的是:
‘杭研’并没有在词典中,但是jieba的Viterbi算法也将其识别了出来。
这时我们就需要考虑HMM这个参数了,关于HMM(Hidden Markov Model,HMM:隐马尔可夫模型),如果深究,那就需要另外一篇博文了,所以我们只要能理解官方给出的这句话即可:对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
可能说的比较干涩,我们实际测一下吧。
补充测试代码:
1 | import jieba |
补充测试结果:
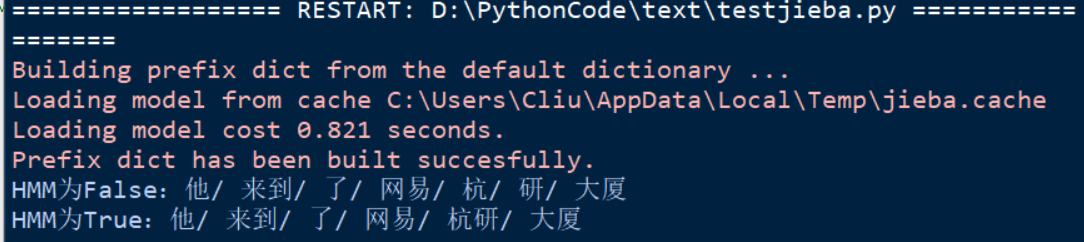
所以一般情况下,使用cut方法,不用考虑HMM这个参数就可以,让它默认为True即可,让Viterbi算法为我们识别新词。HMM也能有效的解决中文中的歧义问题。
启用HMM并不适用所有情况,根据需要开启!!!
关于切词的方法以及切词的注意事项,请大家参考上文给出的两个链接,这里我不再赘述。
基于TF-IDF的关键词提取
相关知识:
对于一个文档,我们肯定不会对所有的词进行聚类,所以我们需要对文档进行关键词提取。
下面我们对TF-IDF做一下简单的说明。如果单讲这个知识点,拿出来又是一篇博文。不过后续我也会写一篇关于它的博文。暂时请大家自行查阅相关资料学习。
TF-IDF是一种统计方法,用于评估一个词对于一个文件集或者语料库中的一份文件的重要程度。
TF(term frequency):指的是某一个给定的词语在该文件中出现的频率。公式如下:
\(tf_i,_j = \frac{n_i,_j}{\sum_k n_k,_j}\)
IDF(Inverse document frequency):是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
\(idf(t,D) = log(\frac{N}{\lvert {d \in D, t \in d}\rvert})\)
关键词提取:
官方给了一个代码示例文件,源代码在这里:关键词提取源码 但是为了结果显示得更清晰一点,我做了些许的改动:
1 | import sys |
先说下用法,官方在文件的第8行给出了用法,即:
1 | python extract_tags.py [file name] -k [top k] |
将这个Extract_tags.py文件和文本文件放在同一目录下,然后给利用如上命令便可得到文本的关键词。默认取得是top10,我改了下取了top20,我们这里做下测试(使用jieba的官方测试文档:《围城》),结果如下:
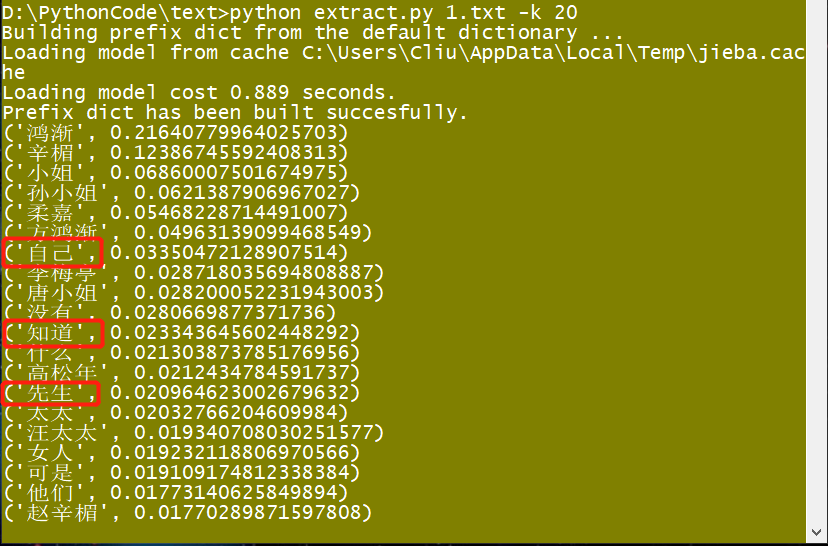
分析:
官方给的代码看着挺长,实际上超简单,其中重要的无非两句话,一句是读文件,另一句则是调用extract_tags()方法,我在原有的基础上设置了withWight=True,因而返回了一个权重值。大家如果嫌麻烦可以对上述关键代码进行抽取,写一个自己的测试。
正如上图所示,‘自己’、‘知道’、‘先生’等等等等,像这些词语都是些没有实际意义的单词,所以在聚类的时候这些单词不应该做为聚类(或者分类)的标准,它们属于stop_words,中文的意思就是停用词,所以我们接下来处理这个问题。
去除停用词
去除停用词,我们需要知道哪些属于停用词,我在CSDN上找到了一个1893规模的停用词表,链接如下:最全中文停用词表整理(1893个)。
我们接下来的工作思路是这样的,对《围城》(文件1.txt)进行切词,方法就是之前的cut(),读取StopWords文件,对比每个切分出来的单词是否是停用词,如果不是则加入到一个list中,然后再将这个list的内容存到另一个文件2.txt中,对文件2.txt使用之前说到的官方给的关键词提取文件做关键词提取即可。
去除停用词代码如下:
1 | import sys |
结果:
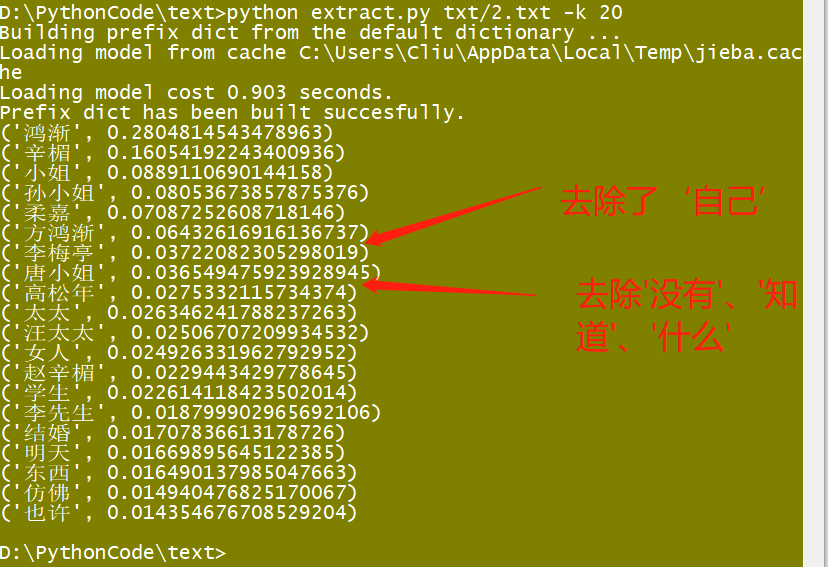
分析:
由上图可见,我们的去停用词的效果还不错。
最后:
这篇博客先写到这里,下一篇博客我会讲到jieba中文分词的进阶篇。感谢阅读,如有问题可以通过邮件与我交流,邮箱:cliugeek@us-forever.com