正如题目那样,这次的学习是StackOverflow上的一个案例,它的地址为https://stackoverflow.com/questions/9413216/simple-digit-recognition-ocr-in-opencv-python,但是源地址上的代码略微有点旧,很多函数在OpenCV3中有了些许的改动,所以我还是会贴上我自己改正过后的代码,然后附上我对作者的思路的理解整理以及对所有代码的理解,如有问题,欢迎和我进行沟通交流,邮箱地址:cliugeek@us-forever.com
思路:
整体的思路:我们需要有一个训练(其实严格意义上说不上是训练,其实我们最终要做的是每个数字的特征提取并且将他们与实际的数字字符一一对应起来,姑且就称这个过程为“训练”吧)的图像,然后我们提取其中所有的数字的特征,然后根据一一对应的的关系,将特征和对应的字符存储起来,以便我们后续做其他图像中的数字识别使用。
所以先贴一下训练用到的数据图:
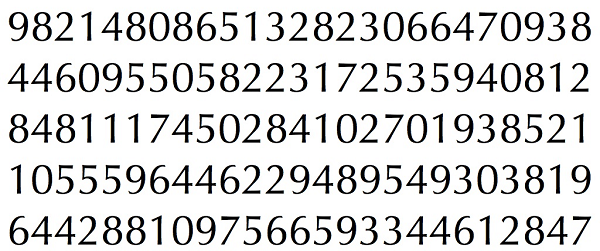
其实这样的训练数据存在着一个问题,那就是所有的字母都是相同的字体和大小,所以整体的鲁棒性很受影响。所以这是本程序需要做继续优化的地方。
接下来我们讲具体的训练过程:
1 加载图像
2 检测数字(通过轮廓查找找,并且通过对检测到的字母的面积和高度做相应的约束,来避免错误的检测)
3 对检测到的字母绘制边框
4 每绘制出一个边框,我们就需要在键盘上键入相应的数字键,这一步很关键,否则会导致我们训练过程无效,导致后面一系列的工作无法进行
5 当我们按下相应的数字键之后,边框里面的东西便会进行重新的resize,变成10x10的大小,然后将其存入到一个100维的数组中(其实就是将这些像素值都存了进去作为我们的特征提取),相应的也会将我们键入的数字存到另一个data文件当中去
6 训练过程完成之后,系统生成两个data文件。在手动数字分类结束时,训练数据(其实就是上面给大家的那张图像)中所有的数字,都已经由我们手工标记,结果如下:

下面就是针对上述过程的代码:
1 | import sys |
代码其实也很简单,所以简单的说一下,首先对图像进行灰度化,然后进行高斯去噪,再然后做二值化。接下来进行轮廓检测,然后对每个检测到的轮廓在面积和高度上进行控制,如果符合设定的标准就进行画框、resize和display,同时将输入的key进行相应的存储,到最后进行save,将他们分别存到generalsamples.data和generalresponses.data中。
接下来进行测试部分,同样先给出测试所用的图像:

再然后就是测试部分的步骤:首先将刚才我们生成的data文件load进来,也就是将刚才的模型加载到内存中,然后我们用KNN(K邻近值法,选取与当前的测试图像中最相近的作为我们预测出来的值)做预测,然后针对于检测出来的每个轮廓都进行这样的操作,预测出来的图像,我们通过puttext方法放到将要生成的图像out上,最后将原图im和生成图out显示出来。
代码如下:
1 | import cv2 |
这部分的代码其实按照刚才的流程理解就可以,所以不再赘述。
最后给大家看下效果:
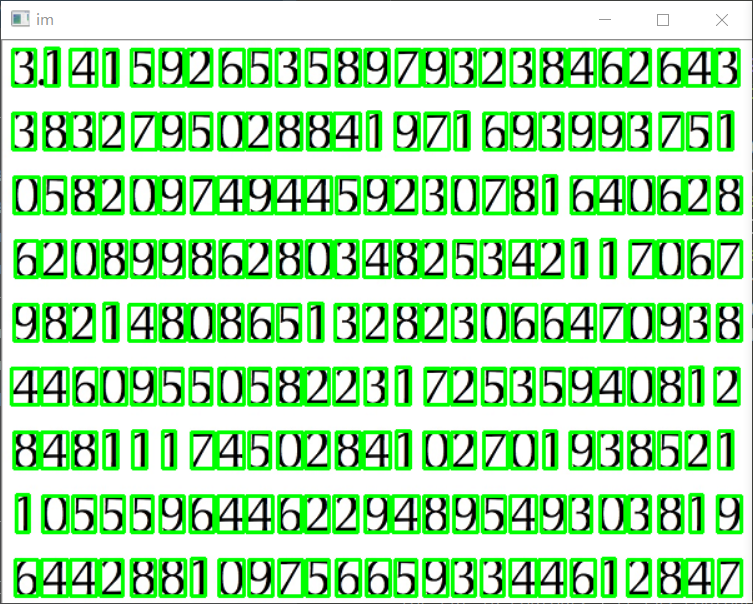
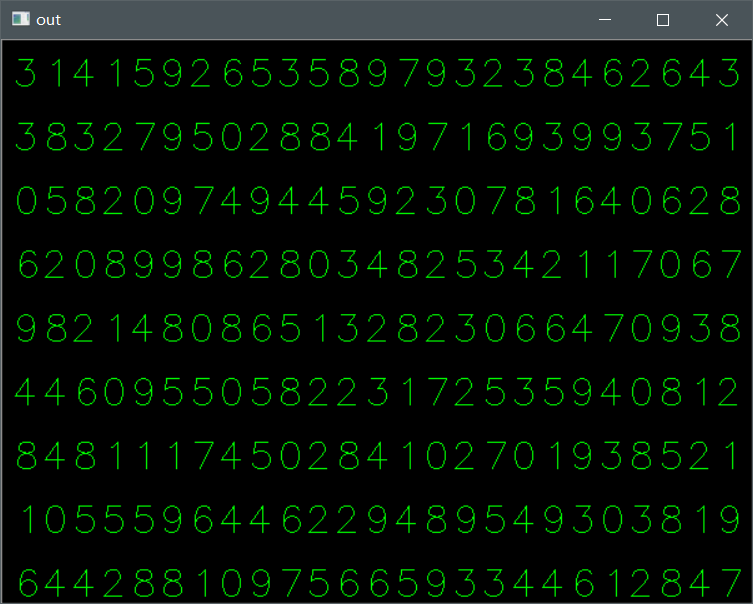
我仔细对比了一遍,准确率可以达到100%。对于这个简单的例子,这样的结果可以称得上完美吧。
以上就是本次学习的所有内容。感谢驻足~