jieba中文分词工具使用进阶篇,废话不多说吗,我们开始本次的学习吧~
如何让分词的更加准确
我们之前举得例子有些文本其实很简单,我们后来确实换了官方的测试文本《围城》,但是均没避免一个问题,这些测试例都十分地中规中矩。在实际中需要我们做分词的文本可能是多种多样的,这时候的切词有可能会不太特别理想,导致分词的不准确。
那我们不妨下一个别的电子书(这里我下载的是《斗破苍穹》,为了测试我只用了第一章的文本),然后再进行切词,看下是否存在这样的问题。这里我们稍微改改上次的去停用词的代码,代码如下:
1 | import sys |
结果如下:

终于被我们找到了一个切词错误,原文是这样的:
萧媚脑中忽然浮现出三年前那意气风发的少年
按照我们正常的断句,应为:
萧媚/脑中/忽然/浮现….,而jieba却认为“萧媚脑”是一个单词,从而导致此处分词不理想。
jieba考虑了这种情况,而且有很多的应对方案,下面我们先说最简单的。
调整词典
方法1:动态修改词典
使用add_word(word,freq=None,tag=None)和del_word(word)可在程序中动态的修改词典,具体操作如下:
1 | import sys |
结果如下:

果然,这样的方法很直接的把我们原来切错的词变成了正确的词。与add_word()相对应的是delete_word()方法,根据字面意思我们也很容易理解delete_word()方法的作用,这里我就不做过多的演示了,大家在实际场景中直接运用就好了。
方法2:调节词频
使用suggest_freq(segment, tune=True)调节单个词语的词频,使得它更容易被分出来,或者不被分出来。
但是需要注意的是:自动计算的词频在使用 HMM 新词发现功能时可能无效。
所以此时我们在做切词的时候需要把是HMM置为False。我们看下官方给的Demo(如果关闭HMM,很多新发现的词都消失了,所以‘萧媚脑’也消失了,无法做测试,我们的例子也是为了方便大家理解,所以也没必要非得针对这一个词做词频调节),具体的做法如下:
1 | import jieba |
结果:
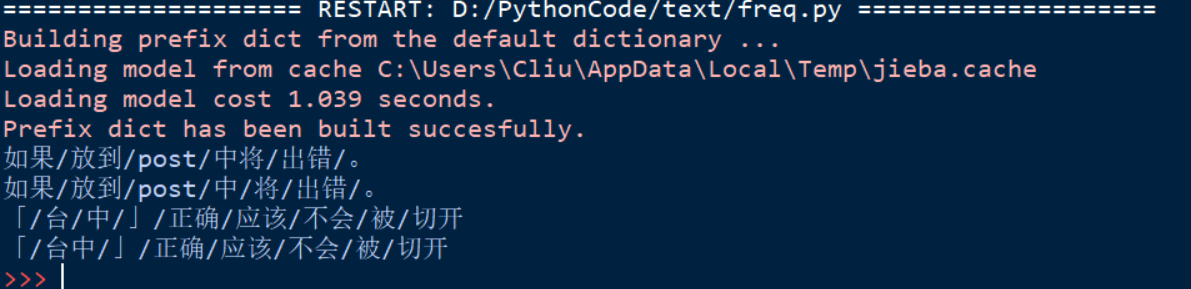
对比下结果,不难发现suggest_freq()的使用方法,通过这样的强调高频词和低频词的方法可以做到分词更准确。
添加自定义词典
比起默认的词典,我们自定义的词典更适合我们自己的文本,这一点是毋庸置疑的。
词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
这里我们的词典为:
1 | 云计算 5 |
我们这个例子也用官方的Demo,代码如下:
1 | import sys |
结果如下:
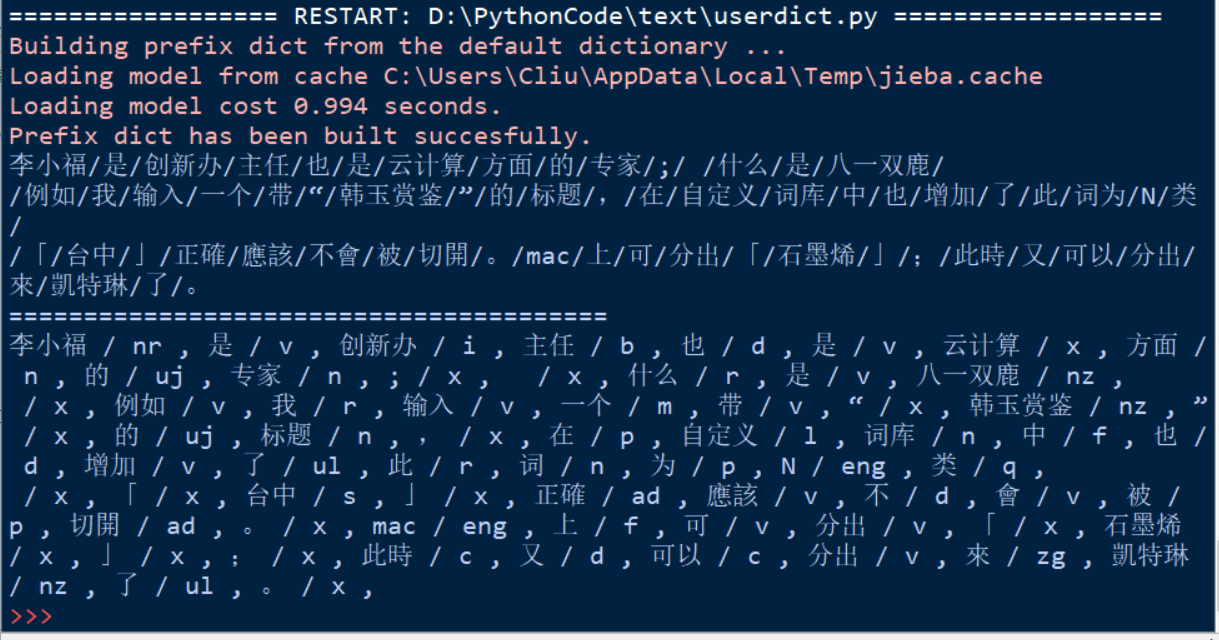
像‘云计算’、‘创新办’等词在没加载词典的时候是不能被识别出来的。像‘石墨烯’等在没有add_word()的时候也是不能识别出来的。可见效果还是不错的。
并行分词
原理:将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升
但是令人遗憾的是,这个模块并不支持Windows平台,原因是因为jieba的该模块是基于python自带的 multiprocessing 模块,而这个模块并不支持Windows。这里我就贴一下用法,使用Linux系统的同学可以自行体验下这个可观的速度提升。
用法:
- jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数
- jieba.disable_parallel() # 关闭并行分词模式
最后
以上所讲的内容在日常的使用中应该是够用了,当然像基于TextRank算法的关键词抽取等内容,我这里并没涉及,并不是因为不重要,而是我对这个算法还不是很了解,硬着头皮写肯定也是照本宣科,效果肯定很差,所以先挖个坑吧,以后再填。
感谢阅读~