咱们今天先聊个概念吧,著名的聚类假设,这也是文本聚类的依据,内容如下:该假设认为,同类的文档相似度较大,而不同类的文档相似度较小。
概念:
对于上述概念,也就是做文本聚类的基础,如果不相关的文档反而相似度高,我们便无法做文本聚类。
接下来再说VSM(Vector Space Model),对于VSM的定义,我在网上搜罗了些资料,如下所示:
Vector space model (or term vector model) is an algebraic model for representing text documents (and any objects, in general) as vectors of identifiers, such as, for example, index terms. It is used in information filtering, information retrieval, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System.
A document is represented as a vector. Each dimension corresponds to a separate term. If a term occurs in the document, its value in the vector is non-zero. Several different ways of computing these values, also known as (term) weights, have been developed. One of the best known schemes is tf-idf weighting.
The definition of term depends on the application. Typically terms are single words, keywords, or longer phrases. If the words are chosen to be the terms, the dimensionality of the vector is the number of words in the vocabulary (the number of distinct words occurring in the corpus).
拙劣的翻译:
向量空间模型是用来表示文本文档(通常也包含一些对象)的特征向量的代数模型,例如索引词项。它被应用于信息过滤、信息检索、索引和相关度计算。这个模型最早被应用于SMART信息检索系统。
一个文本文档表示一个向量。每一个维度相当于一个单独的词项(term)。如果一个词项(term)出现在一个文档中,那么它在表示该文档的向量中对应项不为0.有一些计算这些词项(term)权重的方法被逐渐提出来,其中最著名的方法就是tf-idf权重计算方法。
对于词项(term)的定义依赖于应用。一般而言,词项(term)可以是单词、关键字、或者长短语。如果单词作为词项(term),那么向量中的维度就是词汇表中的单词的个数(出现在文档全集中所有不同的单词的数量)。
小荔枝:
举个荔枝吧 ,方便理解上述的概念。首先假设有这样两个文本
1.我来到北京清华大学
2.他来到了网易杭研大厦
分词结果为:我/来到/北京/清华大学和他/来到/了/网易/杭研/大厦统计所有文档的词集合:我/来到/北京/清华大学/他/了/网易/杭研/大厦,按照1983停用词去除停用词后结果为:来到/北京/清华大学/网易/杭研/大厦
我们对这两个文本构建向量,结果如下
| 来到 | 北京 | 清华大学 | 网易 | 杭研 | 大厦 | |
|---|---|---|---|---|---|---|
| 文本1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 文本2 | 1 | 0 | 0 | 1 | 1 | 1 |
相信你已经对VSM的认识有了一个大致的轮廓,但是细心的你也可能发现了,我们在上述的例子中计算term值的方法仅仅只是计数,这样的term值是否有意义呢?我们是否能用这样的方法直接进行接下来的计算呢?对于前一个问题,答案是肯定的。不管在此基础上做什么样的改进,我们最基础的就是统计单词出现的次数,那就让我们先把上述的代码实现一下吧(与该文件同目录下有个名为txt1的文件夹,里面有1.txt和2.txt两个文件,内容分别是上述所说的两个文档,我们在上次RmStopWord.py的基础上再做修改):
1 | import sys |
运行结果:
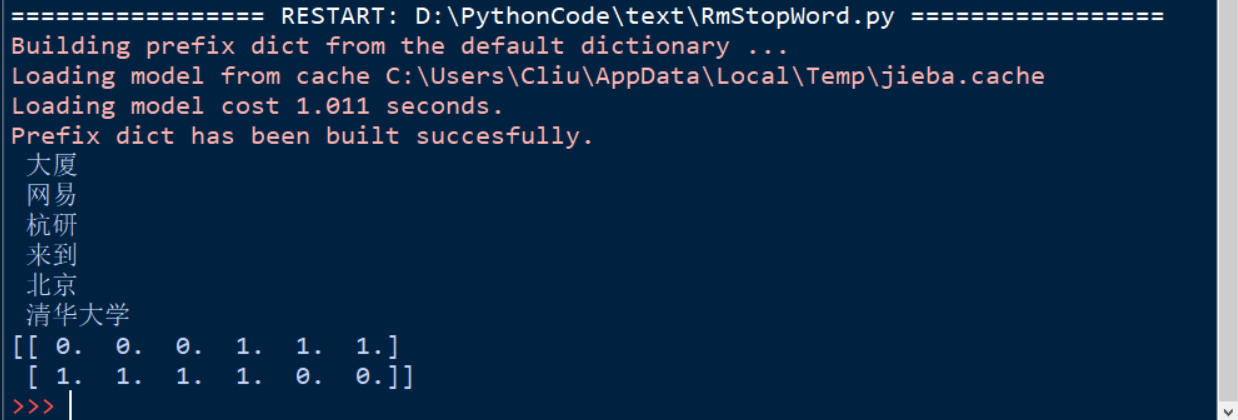
分析:
上述结果不言而喻,那么我们接着讨论,显而易见,我既然提出了第二个疑问就一定有它被提出的道理,仅仅只计算term值的方法显然存在问题,我们再随便举个例子,文本1中北京只出现了1次,但是文本1中只有3个单词,文本2中北京出现了10次但是文本2中有1000个单词,那我们用上述的方法显然不合适。所以接下来我们便要讲一个最著名的方法tf-idf计算权值的方法。
TF-IDF(term frequency–inverse document frequency)
维基百科和百度百科上的讲的很清楚,这里截取概念方便大家阅读,更详细的内容请参考前面所说的两个百科。
TF-IDF是一种统计方法,用以评估一个词(term)对于一个文件集或者一个语料库中的一份文件的重要程度。一个词(term)的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
原理:
TF-IDF的主要思想是:如果某个词或短语(term)在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语(term)具有很好的类别区分能力,适合用来分类。如果包含词条term的文档越少,也就是n越小,则IDF越大,则说明词条term也具有很好的类别区分能力。
思考:
现在想一下我们刚才提出的问题,针对我们上述的问题:同一词语在长文件里可能会比短文件有更高的词数,而不管该词重要与否。那么我们对词数做归一化就可以了,而TF就帮我们做了这样的事。那么我们就先给出TF的运算公式吧。
\(tf_i,_j = \frac{n_i,_j}{\sum_k n_k,_j}\)
TF公式解读:上式中分子是该词在文件中出现的次数,而分母则是该词在文件中出现的词数之和。
我们再讲个小问题:
如果某一类文档C中包含词条t的文档数为m,而其他类包含t的文档总数为k,显然所有包含t的文档数n=m+k,而当m变大的时候,n也变大,这是后按照IDF的计算方法计算得到的IDF值会变小,也就相对应的说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文件中频繁出现,则说明该词条能够很好的代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。其实这就是IDF的不足。
针对这个问题,我的想法是TF-IDF用来做信息检索和数据挖掘,为了获取更精准的效果,我们宁愿忽略这样不足来换取更加理想的效果(也就是TF-IDF计算出更大的权值)。(这里我的理解是这样的,如果有人有更好的解释,欢迎与我进行讨论,邮箱:well@weaf.top)
那么接下来就该给出IDF的计算公式了:
\(idf(t,D) = log(\frac{N}{\lvert {d \in D, t \in d}\rvert})\)
IDF公式解读:
|D|:语料库中文件的总数
分子为包含该词条t的文件数目,如果该词条不在语料库中,就会导致分母为零,因此一般使用1。
那就接着我们上述代码,运用TF-IDF,把对应的矩阵的单纯计数转换成权值计算吧:
1 | ··· |
结果:
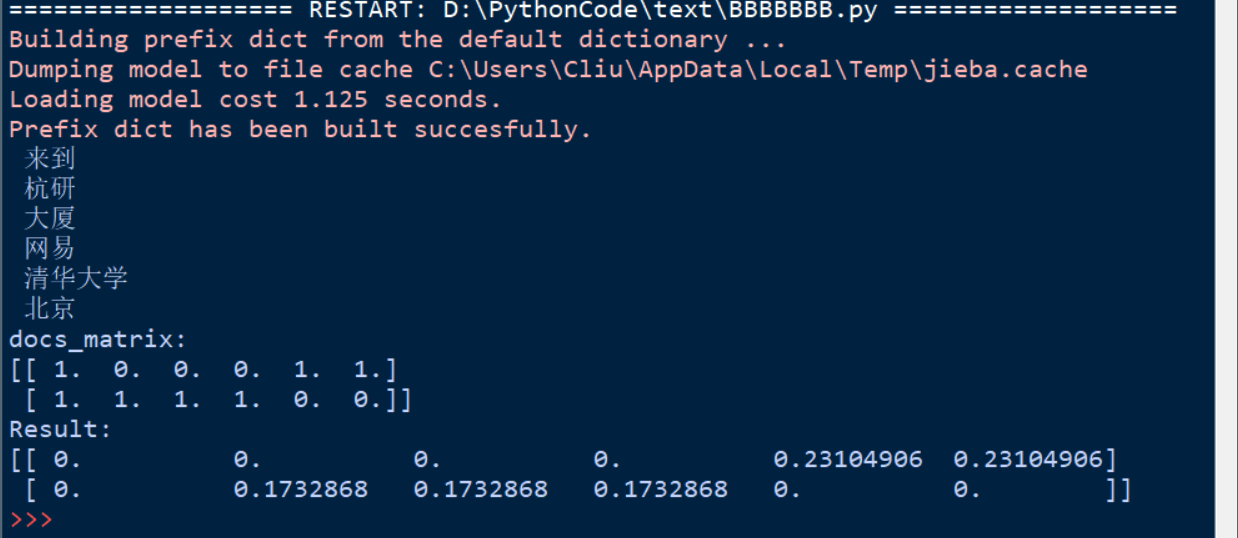
本次的学习会用到很多numpy的知识,请大家自行查阅。如有兴趣,请思考为什么在新的权值矩阵中“来到”一词的权重变成了0。感谢大家的阅读~