1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
|
"""
Created on Sun Mar 25 15:16:23 2018
@author: milittle
"""
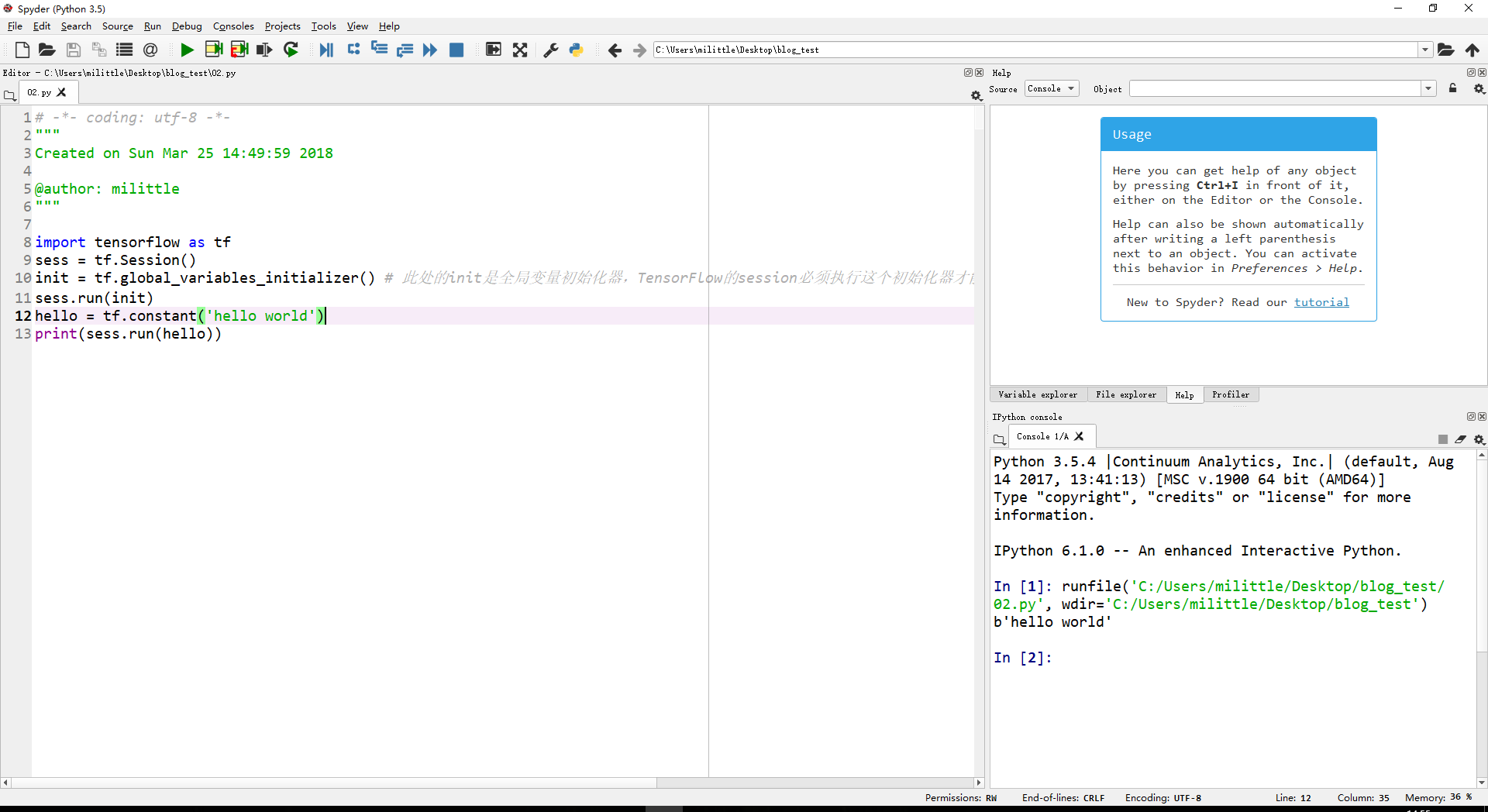
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
fashion_mnist = input_data.read_data_sets('input/data', one_hot = True)
label_dict = {
0: 'T-shirt/top',
1: 'Trouser',
2: 'Pullover',
3: 'Dress',
4: 'Coat',
5: 'Sandal',
6: 'Shirt',
7: 'Sneaker',
8: 'Bag',
9: 'Ankle boot'
}
sample_1 = fashion_mnist.train.images[47].reshape(28,28)
sample_label_1 = np.where(fashion_mnist.train.labels[47] == 1)[0][0]
sample_2 = fashion_mnist.train.images[23].reshape(28,28)
sample_label_2 = np.where(fashion_mnist.train.labels[23] == 1)[0][0]
print("y = {label_index} ({label})".format(label_index=sample_label_1, label=label_dict[sample_label_1]))
plt.imshow(sample_1, cmap='Greys')
plt.show()
print("y = {label_index} ({label})".format(label_index=sample_label_2, label=label_dict[sample_label_2]))
plt.imshow(sample_2, cmap='Greys')
plt.show()
n_hidden_1 = 128
n_hidden_2 = 128
n_input = 784
n_classes = 10
def create_placeholders(n_x, n_y):
"""
为sess创建一个占位对象。
参数:
n_x -- 向量, 图片大小 (28*28 = 784)
n_y -- 向量, 种类数目 (从 0 到 9, 所以是 -> 10种)
返回参数:
X -- 为输入图片大小的placeholder shape是[784, None]
Y -- 为输出种类大小的placeholder shape是[10, None] None在这里表示以后输入的数据可以任意多少
"""
X = tf.placeholder(tf.float32, [n_x, None], name="X")
Y = tf.placeholder(tf.float32, [n_y, None], name="Y")
return X, Y
X, Y = create_placeholders(n_input, n_classes)
print("Shape of X: {shape}".format(shape=X.shape))
print("Shape of Y: {shape}".format(shape=Y.shape))
def initialize_parameters():
"""
参数初始化,下面是每个参数的shape,总共有三层
W1 : [n_hidden_1, n_input]
b1 : [n_hidden_1, 1]
W2 : [n_hidden_2, n_hidden_1]
b2 : [n_hidden_2, 1]
W3 : [n_classes, n_hidden_2]
b3 : [n_classes, 1]
返回:
包含所有权重和偏置项的dic
"""
tf.set_random_seed(42)
W1 = tf.get_variable("W1", [n_hidden_1, n_input], initializer = tf.contrib.layers.xavier_initializer(seed = 42))
b1 = tf.get_variable("b1", [n_hidden_1, 1], initializer = tf.zeros_initializer())
W2 = tf.get_variable("W2", [n_hidden_2, n_hidden_1], initializer = tf.contrib.layers.xavier_initializer(seed = 42))
b2 = tf.get_variable("b2", [n_hidden_2, 1], initializer = tf.zeros_initializer())
W3 = tf.get_variable("W3", [n_classes, n_hidden_2], initializer=tf.contrib.layers.xavier_initializer(seed = 42))
b3 = tf.get_variable("b3", [n_classes, 1], initializer = tf.zeros_initializer())
parameters = {
"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3
}
return parameters
tf.reset_default_graph()
with tf.Session() as sess:
parameters = initialize_parameters()
print("W1 = {w1}".format(w1=parameters["W1"]))
print("b1 = {b1}".format(b1=parameters["b1"]))
print("W2 = {w2}".format(w2=parameters["W2"]))
print("b2 = {b2}".format(b2=parameters["b2"]))
def forward_propagation(X, parameters):
"""
实现前向传播的模型 LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX
上面的显示就是三个线性层,每一层结束以后,实现relu的作用,实现非线性功能,最后三层以后用softmax实现分类
参数:
X -- 输入训练数据的个数[784, n] 这里的n代表可以一次训练多个数据
parameters -- 包括上面所有的定义参数三个网络中的权重W和偏置项B
返回:
Z3 -- 最后的一个线性单元输出
"""
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
Z1 = tf.add(tf.matmul(W1,X), b1)
A1 = tf.nn.relu(Z1)
Z2 = tf.add(tf.matmul(W2,A1), b2)
A2 = tf.nn.relu(Z2)
Z3 = tf.add(tf.matmul(W3,A2), b3)
return Z3
tf.reset_default_graph()
with tf.Session() as sess:
X, Y = create_placeholders(n_input, n_classes)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
print("Z3 = {final_Z}".format(final_Z=Z3))
def compute_cost(Z3, Y):
"""
计算cost
参数:
Z3 -- 前向传播的最终输出([10, n])n也是你输入的训练数据个数
Y --
返回:
cost - 损失函数 张量(Tensor)
"""
logits = tf.transpose(Z3)
labels = tf.transpose(Y)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = labels))
return cost
tf.reset_default_graph()
with tf.Session() as sess:
X, Y = create_placeholders(n_input, n_classes)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
print("cost = {cost}".format(cost=cost))
def model(train, test, learning_rate=0.0001, num_epochs=16, minibatch_size=32, print_cost=True, graph_filename='costs'):
"""
实现了一个三层的网络结构: LINEAR->RELU->LINEAR->RELU->LINEAR->SOFTMAX.
参数:
train -- 训练集
test -- 测试集
learning_rate -- 优化权重时候所用到的学习率
num_epochs -- 训练网络的轮次
minibatch_size -- 每一次送进网络训练的数据个数(也就是其他函数里面那个n参数)
print_cost -- 每一轮结束以后的损失函数
返回:
parameters -- 被用来学习的参数
"""
tf.reset_default_graph()
tf.set_random_seed(42)
seed = 42
(n_x, m) = train.images.T.shape
n_y = train.labels.T.shape[0]
costs = []
X, Y = create_placeholders(n_x, n_y)
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
epoch_cost = 0.
num_minibatches = int(m / minibatch_size)
seed = seed + 1
for i in range(num_minibatches):
minibatch_X, minibatch_Y = train.next_batch(minibatch_size)
_, minibatch_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X.T, Y: minibatch_Y.T})
epoch_cost += minibatch_cost / num_minibatches
if print_cost == True:
print("Cost after epoch {epoch_num}: {cost}".format(epoch_num=epoch, cost=epoch_cost))
costs.append(epoch_cost)
plt.figure(figsize=(16,5))
plt.plot(np.squeeze(costs), color='#2A688B')
plt.xlim(0, num_epochs-1)
plt.ylabel("cost")
plt.xlabel("iterations")
plt.title("learning rate = {rate}".format(rate=learning_rate))
plt.savefig(graph_filename, dpi = 300)
plt.show()
parameters = sess.run(parameters)
print("Parameters have been trained!")
correct_prediction = tf.equal(tf.argmax(Z3), tf.argmax(Y))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print ("Train Accuracy:", accuracy.eval({X: train.images.T, Y: train.labels.T}))
print ("Test Accuracy:", accuracy.eval({X: test.images.T, Y: test.labels.T}))
return parameters
train = fashion_mnist.train
test = fashion_mnist.test
parameters = model(train, test, learning_rate = 0.001, num_epochs = 16, graph_filename = 'fashion_mnist_costs')
|